Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services)或者通用的网络爬虫。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrapy的原理结构图如下:


从上图中,我们可以看到scrapy主要包括如下这些组件:
(1)引擎Scrapy
用来处理整个系统的数据流处理,触发事务(框架核心)。
(2)调度器Scheduler
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
(3)下载器Downloader
用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
(4)爬虫Spiders
爬虫是主要干活的,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(5)项目管道Pipeline
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
(6)下载器中间件Downloader Middlewares
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
(7)爬虫中间件Spider Middlewares
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
(8)调度中间件Scheduler Middewares
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
(1)引擎从调度器中取出一个链接(URL)用于接下来的抓取
(2)引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
(3)爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。若是解析出的是链接(URL),则把URL交给Scheduler等待抓取。
Scrapy的安装与配置
安装依赖和Scrapy列表如下(其实直接执行pip install scrapy命令,提示有依赖缺失后,在逐一解决即可):

使用scrapy框架生成爬虫工程目录结构
执行scrapy startproject testscrapy命令即可创建爬虫工程的基本目录结构,如下:
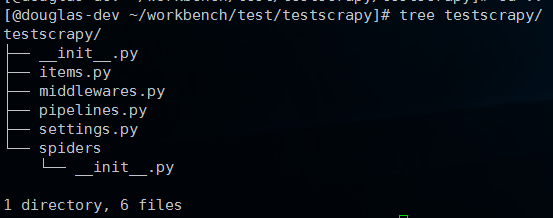
其中,
scrapy.cfg #项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py #设置数据存储模板,用于结构化数据,如:Django的Model
pipelines #数据处理行为,如:一般结构化的数据持久化
settings.py #配置文件,如:递归的层数、并发数,延迟下载等
spiders #爬虫目录,如:创建文件,编写爬虫规则
基于Scrapy编写自己的爬虫
前提声明,以爬取某XXOO网站为例说明:
(1)新建Item,代码如下:
1 | import scrapy |
(2)在spiders目录新建一个xxxspider.py文件,定义一个继承自scrapy.Spider的类,代码示例如下:
1 | import scrapy |
(3)编写pipeline用来保存图片
编写一个继承自ImagesPipeline的自定义图片保存的Pipeline,如下:
1 | class JianDanImagesPipeline(ImagesPipeline): |
(4)在settings.py中做一些基本的配置
常用的配置有:
1 | ROBOTSTXT_OBEY = False //是否遵循robot.txt协议 |
(5)在项目目录执行scrapy crawl "爬虫名"命令即可启动爬虫。
TODOLIST
(1)使用Scrapy搭建分布式爬虫集群?
学习文档参考于:
http://blog.csdn.net/u012150179/article/category/2345511
http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
Scrapy中文文档:http://scrapy-chs.readthedocs.io/zh_CN/0.24/index.html
http://www.cnblogs.com/qiyeboy/p/5449266.html
xpath教程:http://www.w3school.com.cn/xpath/index.asp