nagios配置中基本概念
nagios配置中一些主要的概念有:
1 | 主机host |
备注:主机组、服务组、联系人组的配置方法参见http://www.361way.com/nagios-groups/2855.html文档
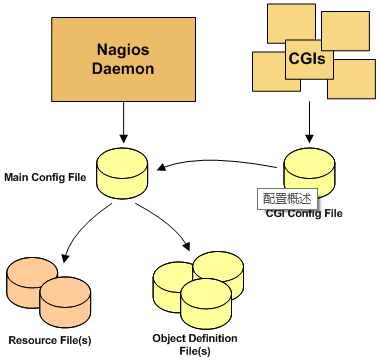
nagios的配置文件
nagios配置文件有:
(1)主配置文件${NAGIOS_HOME}/etc/nagios.cfg
它是nagios的主配置文件,Nagios后台进程启动时,会指定加载该文件。
(2)资源文件${NAGIOS_HOME}/etc/resource.cfg
资源文件可用于存储用户定义的宏。资源文件的主要目的是使用它们来存储敏感的配置信息(如密码)。
(3)CGI配置文件${NAGIOS_HOME}/etc/cgi.cfg
该配置文件用来控制相关cgi脚本,如果想在nagios的web监控界面执行cgi脚本,例如重启nagios进程、关闭nagios通知、停止nagios主机检测等,这时就需要配置cgi.cfg文件
(4)对象定义文件${NAGIOS_HOME} /etc/objects/*.cfg
对象定义文件用于定义主机、服务、主机组、联系人、联系人组以及命令等。我们可以在此定义所有要监视的内容,以及如何监视它们。 我们可以使用主配置文件nagios.cfg中的cfg_file和/或cfg_dir指令来指定一个或多个对象定义文件。对象配置文件有:
1 | hosts.cfg #用来定义主机和主机组 |
详细的配置文件如下:

备注:当我们修改完nagios的配置文件后,可以执行命令./bin/nagios -v etc/nagios.cfg来检查配置文件是否正确。
nagios各个配置文件的依赖关系以及被加载的进程图
nagios的host/service配置样例
1 | define host { |
nagios的调度机制中涉及的一些配置参数
在nagios的调度机制中,涉及到一些概念:
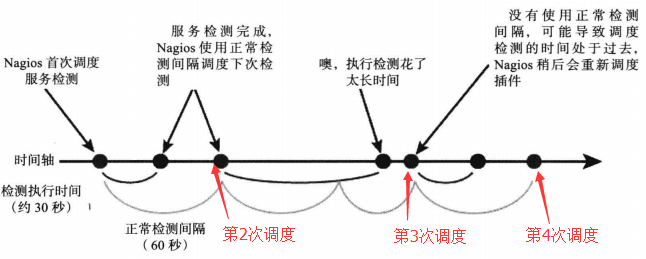
(1)check_interval
表示的nagios检查的周期,是正常检测间隔。
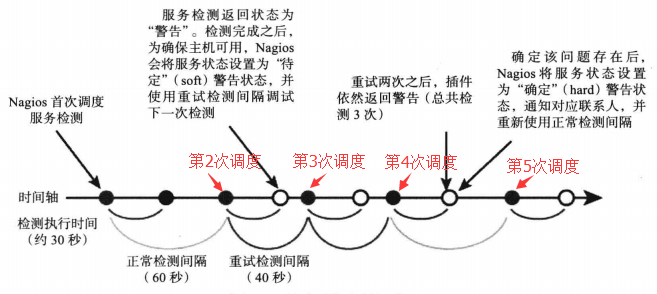
(2)max_check_attempts
表示如果nagios在某个采集周期中,发现监控项是异常的,那么不会立即认为这个监控项是异常的,将其标记为SOFT state。然后继续去监控,会尝试最多max_check_attempts-1次采集。如果中间某次恢复正常,则认为服务恢复。如果max_check_attempts次采集均为异常,则认为这个监控项是异常的,将其标记为HARD state。
(3)retry_interval
在max_check_attempts次重试检查的过程中,每两次之间的时间间隔。
(4)notification_interval
当服务被任务是HARD state后,会发送报警通知。这个表示本次发出报警后,还间隔多长时间,才可以继续发送报警。
(5)interval_length
interval_length决定了上面check_interval,retry_interval,notification_interval等参数的单位。如果interval_length=60(interval_length的单位是秒),表示上面check_interval,retry_interval,notification_interval的单位是分钟。注意,interval_length默认值是60,一般不需要去修改这个选项。
(6)notification_options
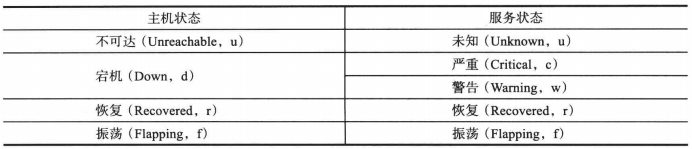
该配置用来决定在什么时机发送告警,通常有如下选项:
1 | d —— DOWN state时发出告警 |
如果不指定任何选项,则上面的所有情况都会发出告警。详细选项如下:
结合如下两张图来理解上述的一些概念,其中“正常检测间隔”即check_interval,“重试检测间隔”即retry_interval。
nagios自定义插件编写
nagios自定义插件编写如下:

nagios插件可以用任何语言编写,自定义插件要满足两个特征:一是脚本必须有返回码(0是正常,1是警告,2是严重,3是未知);二是脚本需要输出一段可读的文本,该文本会出现在nagios的GUI的监控状态中。
nagios的告警等级
所谓nagios_level,即我们通过nagios plugin检查数据时的返回值。其取值范围和含义如下:
1 | "0",代表 "OK",服务正常; |
nagios告警的配置
(1)在command.cfg配置发送邮件、短信或微信报警的命令command
(2)在contact.cfg或contactgroup.cfg中配置联系人或联系人组,并关联到命令
(3)在host.cfg或service.cfg中定义host/service时,通过contact_groups指定联系人或联系人组,即有异常则向指定的联系人/联系人组发送告警。
nagios.cfg的一些重要配置项
nagios.cfg的一些重要配置项有:
1 | accept_passive_host_checks=1 #是否接收host的被动检查结果,即开启host的被动检查。1表示开启。 |