Flume简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,目前已经是Apache的一个子项目。在Flume中有一个event的概念,event就是Flume处理数据的最小单元。
Flume的内部是由Source、Channel以及Sink三个组件组成:
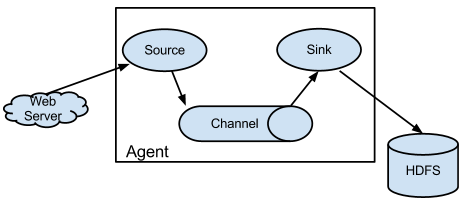
(1)Source
Source组件用来与要搜集的外部数据源做交互,Source支持很多的数据源,例如文件以及thrift等RPC数据。
(2)Sink
Sink组件用来与外部存储做交互,Sink支持向文件系统、数据库、hadoop存数据。
(3)Channel
Channel组件是用来连接Source和Sink的数据通道,当前有如下几个channel可供选择(比较常见的是前三种channel):
A)Memory Channel
把event放到内存队列当中,使用这种channel的优点是速度最快的channel、容易配置 。缺点是当flume agent挂掉时会导致数据丢失。
B)File Channel
持久化event到磁盘 ,可靠性很好 ,但是速度慢。
C)JDBC Channel
event持久化存储到DB。现在仅支持嵌入式的derby ,可以防止丢数据了,而且还提供了一些数据管理 。但是持久化到DB仅支持derby,选择较少,速度没有memory channel快
D)Psuedo Transaction Channel
Flume在生产环境中的应用
Flume在生产环境的部署结构非常灵活,如下为一种部署架构的例子:
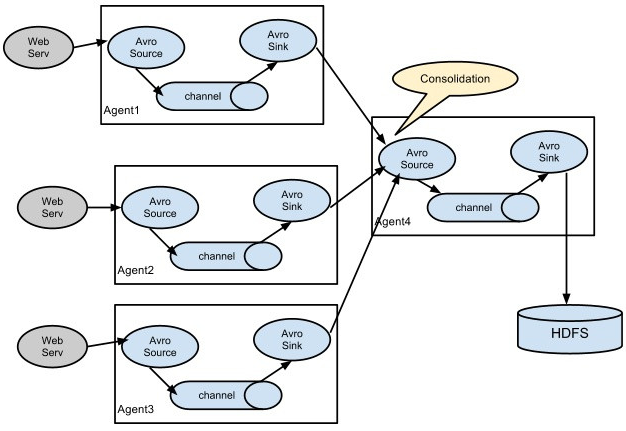
Flume具有如下的特性:
(1)Channel中的数据只有在Sink组件发送成功后才会被删除
(2)在整个数据的传输过程中流动的是event,event可以理解为是flume中数据传输的基本单位,event表现为一条条的数据,其事务保证是event级别
(3)flume支持多级flume的agent,支持扇入(fan-in)和扇出(fan-out)
Flume的配置和安装
(1)Flume下载和安装
在https://flume.apache.org/download.html中下载Apache Flume二进制版本,解压到目标目录即可。
(2)Flume配置
A)JAVA环境变量配置,有两种方式
配置JDK环境变量(PATH,JAVA_HOME, CLASS_PATH),或者在${JAVA_HOME}/conf/flume-env.sh中增加export JAVA_HOME=/root/prod/jdk1.7.0_80即可。后者很好用,这样就不会对操作系统中已有的应用程序带来影响。
B)Flume自身的配置
在conf目录新建一个flume的配置文件,假设为flume-my.conf,配置举例如下:
1 | # flume-my.conf: A single-node Flume configuration |
备注:agent1是自定义的agent的名称
(3)启动flume命令
1 | cd /root/prod/apache-flume-1.7.0-bin/ && ./bin/flume-ng agent --conf /root/prod/apache-flume-1.7.0-bin/conf/ --conf-file /root/prod/apache-flume-1.7.0-bin/conf/flume-my.conf --name agent1 -Dflume.root.logger=INFO,console |
备注:
A)–name agent_name指定的flume agent名称要与flume配置文件中自定义的agent名称一致
B)-Dflume.root.logger=INFO,console中表示flume自身的日志输出到控制台中,如果是-Dflume.root.logger=INFO,LOGFILE表示将日志输出到文件中
Flume中的拦截器Interceptor
Flume中拦截器的作用就是对于event中header的部分可以按需塞入一些属性,当然你如果想要处理event的body内容,也是可以的,但是event的body内容是系统下游阶段真正处理的内容,如果让Flume来修饰body的内容的话,那就是强耦合了,这就违背了当初使用Flume来解耦的初衷了。
Flume的闲杂知识
在Flume中,event是流动的数据的最小单元,就是我们理解的一条日志。event包括event header和event body两部分。event body就是我们实际的数据,event header可以根据用户自定义配置,例如很多interceptor就是往event header中写入信息,供下游的flume组件来使用。从数据结构上来说,event由头Map<String, String> headers和身体body两部分组成:Headers部分是一个map,body部分可以是String或者byte[]等。其中body部分是真正存放数据的地方,headers部分用于interceptor特性等。

Flume的最佳实践
(1)flume source文件正则的使用
在flume1.7.0的TAILDIR Source中通过正则来匹配数据源文件,例如agent.sources.r2.filegroups.f1 = /root/prod/test-env/input-data/messages(.*)?,如果修改文件的文件名,flume也认为是一个新文件,从而导致数据被重复搜集的问题。有blog反馈这个问题是bug,如https://kknews.cc/other/enx3mk4.html,需要注意下这个问题。
(2)当我们使用agent.sources.r2.filegroups.f1 = /root/prod/test-env/input-data/messages的绝对路径来匹配文件时,无论我们使用move+touch,或者copy+置空的方式来切割日志文件,flume都能正常收集messages文件中日志内容。
Flume自定义Interceptor的开发
待补充