常见的消息队列Message Queue,MQ
(1)RabbitMQ
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
(2)Redis
Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
(3)ZeroMQ
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但是ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty作为传输模块)。
(4)ActiveMQ
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
(5)Kafka/Jafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
如下为Kafka、RabbitMQ以及RocketMQ的一点区别,权威性待验证。
Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
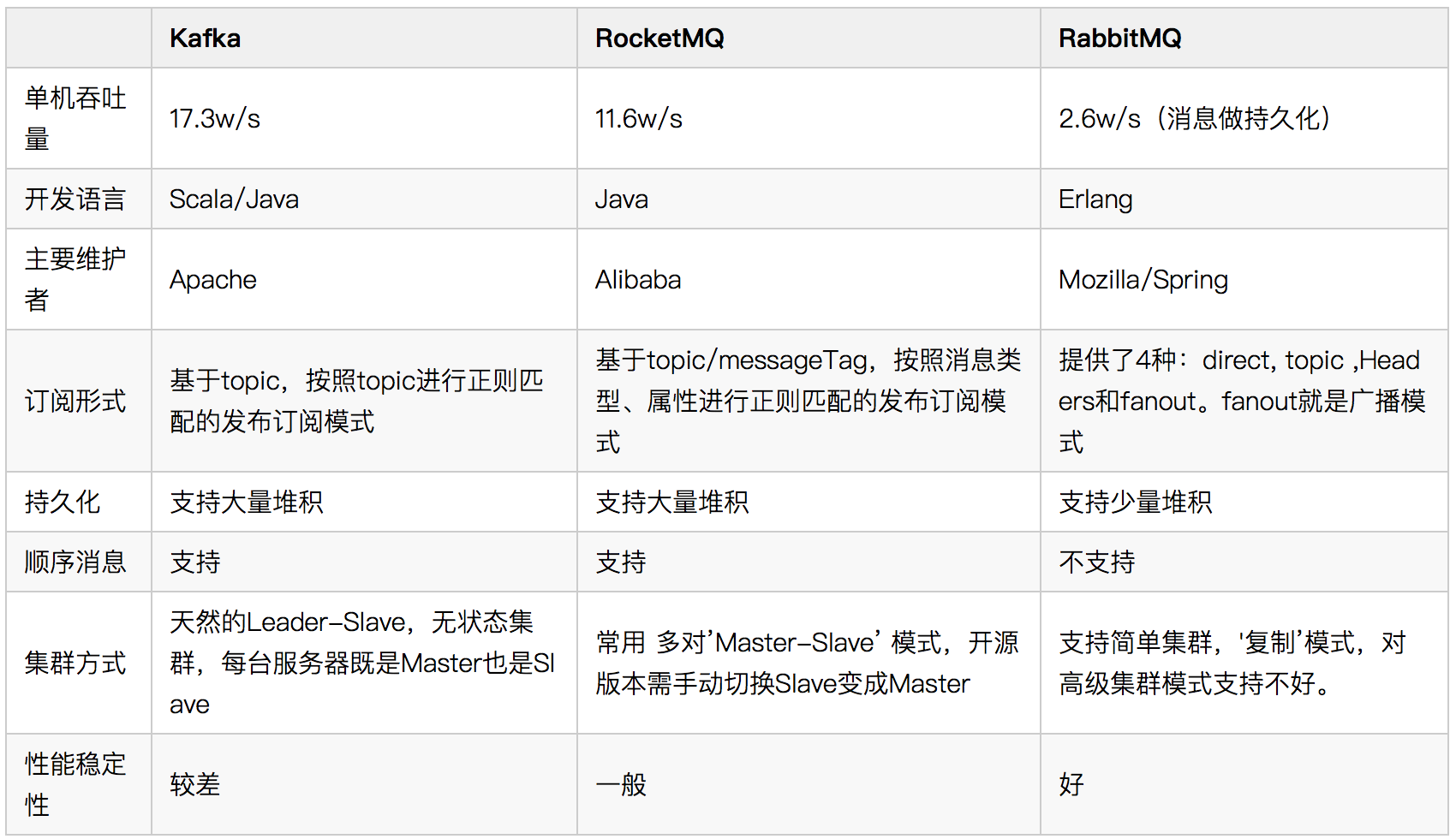
Kafka简介
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写(Scala程序是运行在JDK上的),它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
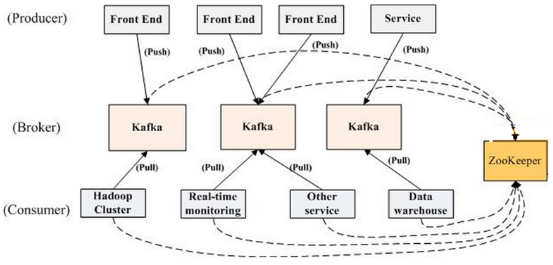
Kafka集群的组成部分有:
(1)Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker 。
(2)Topic
Topic是逻辑上的概念。每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。如下为一个topic的解剖图:
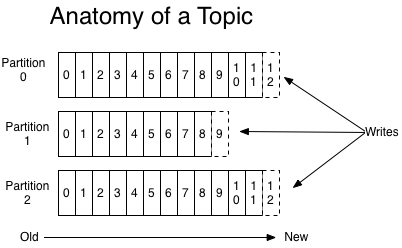
备注:这个topic有3个partition,每一个partition中的数据是按时间有序的。
(3)Partition
Parition是物理上的概念。每个Topic包含一个或多个Partition,每个partition又由一个一个消息组成,每个消息都被标识了一个递增序列号代表其进来的先后顺序,并按顺序存储在partition中。Partition是kafka消息队列组织的最小单位。对于某一个Partition来说,它只会存储在某个broker上(就是某台机器上),而不会分布在多台机器上,当然这个Partition有Replica的话,它的Replica是分布在其他的Broker上的。
(4)Producer
负责发布消息到Kafka broker 。
(5)Consumer
消息消费者,向Kafka broker读取消息的客户端。
(6)Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
(7)Controller
每个Cluster当中会选举出一个Broker来担任Controller,负责处理Partition的Leader选举,协调Partition迁移等工作。
备注:Topic相当于pipe,Partition相当于pipelet。
关于Consumer和Consumer Group的一点补充
传统的消息队列的消息消费有两种模式:
(1)队列模式-Queue
在队列模式中,一条消息只能被某一个消费者消费,一条消息一旦被消费后,其他的消费者就获取不到这条消息了。
(2)发布/订阅模式-Topic
在发布/订阅模式中,消息可以被所有的消费者消费。
在Kafka中,通过使用Consumer Group的机制,Kafka集群就涵盖了上述两种的模式。每一个Consumer都存在于某个Consumer Group中。各个Consumer Group使用发布/订阅模式来消费数据,也就是说每个Consumer Group都可以消费消息队列中的所有消息。而对于单独的一个Consumer Group所包含的所有Consumer,则使用队列模式来消费消息,也就是Consumer Group订阅到的某一条消息,只能被该Group中的某一个Consumer消费。
如果Kafka中,所有Consumer Group都包含一个Consumer的话,那其实就相当于是发布/订阅模式。下图形象地说明了Kafka的消息消费方式:
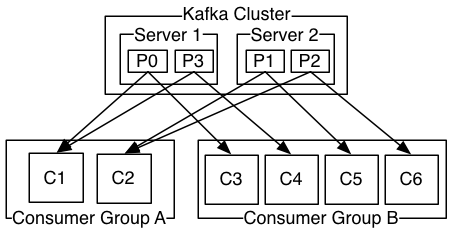
另外,属于同一个Consumer Group的多个Consumer在消费信息时,也有一定的balance策略。当Consumer和Partition的数量相同时,那么每个Consumer都会去消费一个Partition。当Consumer比Partition的数据要少时,那么有些Consumer就会去消费多个Partition。当Consumer比Partition的数据要多时,那么有些Consumer就不会从任何Partition中订阅数据。此部分内容可参见《Kafka深度解析》。
Kafka集群配置和搭建
前提声明:本次部署测试用的是kafka_2.12-0.10.2.0
搭建测试一:单broker的Kafka集群搭建
(1)下载kafka二进制包
(2)启动只有一个节点的应急的zookeeper集群
1 | ./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties |
连接zookeeper集群并测试:./bin/zookeeper-shell.sh 192.168.65.239:2181(备注:zookeeper的默认端口是2181)
(3)启动一个kafka broker
1 | ./bin/kafka-server-start.sh config/server.properties |
(4)创建测试用的topic
1 | # 创建名称为wahaha的topic,有1个partition,复制因子为1(单副本,就是没有备份) |
查看集群中的所有topic信息:./bin/kafka-topics.sh --list --zookeeper 192.168.65.239:2181
备注:也可以在broker配置,使其能够自动创建topic,而不需要手动去创建topic
(5)向Kafka集群中指定的topic写入一些消息
1 | ./bin/kafka-console-producer.sh --broker-list 192.168.65.239:9092 --topic wahaha |
备注:使用Ctrl+D结束输入
(6)消费Kafka集群中指定topic的消息(如下两种方式都是可以的)
1 | ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.239:9092 --topic wahaha --from-beginning |
搭建测试二:多broker的Kafka集群搭建
前提:在同一台物理机上通过启动3个broker进程,来达到搭建有3个broker的Kafka集群,步骤如下:
(1)下载kafka二进制包
(2)启动只有一个节点的应急的zookeeper集群
1 | ./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties |
连接zookeeper集群并测试:./bin/zookeeper-shell.sh 192.168.65.239:2181(备注:zookeeper的默认端口是2181)
(3)启动三个kafka broker
1 | cd config && mv server.properties server-1.properties |
修改config/server-1.properties内容如下:
broker.id=1
listeners=PLAINTEXT://192.168.65.239:9092
log.dir=/tmp/kafka-logs-1
修改config/server-2.properties内容如下:
broker.id=2
listeners=PLAINTEXT://192.168.65.239:9093
log.dir=/tmp/kafka-logs-2
修改config/server-3.properties内容如下:
broker.id=3
listeners=PLAINTEXT://192.168.65.239:9094
log.dir=/tmp/kafka-logs-3
1 | ./bin/kafka-server-start.sh [-daemon] config/server-1.properties #启动监听默认9092端口的broker |
备注:加上-daemon选项,将会在后台启动broker进程;另外,在实际部署kafka集群时,注意listens中的配置格式哦
(4)创建测试用的topic
1 | # 创建名称为wahaha-replicas的topic,有1个partition,复制因子为3(三副本) |
备注:也可以在broker配置,使其能够自动创建topic,而不需要手动去创建topic
(5)向Kafka集群中指定的topic写入一些消息
1 | ./bin/kafka-console-producer.sh --broker-list 192.168.65.239:9093 --topic wahaha-replicas |
备注:broker的端口9092,9093,9094都可以用的。–broker-list只需要随便给下broker的ip:port,不用给全部,参见metadata.broker.list
(6)消费Kafka集群中指定topic的消息(如下两种方式都是可以的)
1 | ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.239:9092 --topic wahaha-replicas --from-beginning |
AMQP协议
AMQP,Advanced Message Queuing Protocol,中文译为高级消息队列协议。AMQP是一个标准开放的应用层的消息中间件(Message Oriented Middleware)协议。AMQP定义了通过网络发送的字节流的数据格式。因此兼容性非常好,任何实现AMQP协议的程序都可以和与AMQP协议兼容的其他程序交互,可以很容易做到跨语言,跨平台。 像ActiveMQ/RabbitMQ都按照AMQP协议来实现,而Kafka是仿照AMQP协议来实现的。
Kafka集群搭建最佳实践
(1)kafka集群最好部署在相同局域网的环境里,不要部署在不同的网络环境里。跨数据中心延迟大,大大影响kafka、zk写入效率以及分区复制效率。
(2)磁盘推荐使用RAID,但是SSD是非必需的。
(3)kafka集群的重要配置项
zookeeper.connect # 必配参数,建议在kafka集群的每台机器都配置所有zk
broker.id # 必配参数,集群节点的标示符,不得重复。取值范围0~n
log.dirs # 配置broker存放数据的位置,不要使用默认的/tmp/kafka-logs
num.partitions # 自动创建topic时默认partition数量。默认是1,为了获得更好的性能,建议修改为更大
default.replication.factor # 自动创建topic的默认副本数量,官方建议修改为2,也就是在kafka集群中同一个消息有两份
metadata.broker.list # 给出一些broker地址,没必要将集群中所有的broker都添加到这个属性中,但是建议最少设置两个,以防止第一个broker不可用。Kafka会自己找到相应topic/partition的leader broker
log.retention.hours # kafka数据保留时间
log.segment.bytes # partition在磁盘的文件不能超过log.segment.bytes大小,如果超过该指,则重新写入一个新文件,即新的segment
(4)在发布数据时,需要通过broker-list来指定broker的ip和port,这里其实不需要把集群中的所有broker都配置上去,因为发布端api可以通过一台broker获取到集群所有的metadata。而订阅数据时,只需要指定zookeeper地址即可。
Kafka的HA设计
(1)Kafka中的HA设计
A)Kafka的Replication机制
Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服务。若该Broker永远不能再恢复,亦或磁盘故障,则其上数据将丢失。而Kafka的设计目标之一即是提供数据持久化,同时对于分布式系统来说,尤其当集群规模上升到一定程度后,一台或者多台机器宕机的可能性大大提高,对Failover要求非常高。因此,Kafka从0.8开始提供High Availability机制。
B)Kafka的Leader Election机制
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。 因为需要保证同一个Partition的多个Replica之间的数据一致性(其中一个宕机后其它Replica必须要能继续服务并且即不能造成数据重复也不能造成数据丢失)。如果没有一个Leader,所有Replica都可同时读/写数据,那就需要保证多个Replica之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证,大大增加了Replication实现的复杂性,同时也增加了出现异常的几率。而引入Leader后,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路),系统更加简单且高效。如下为引入Replication机制后数据的同步过程图:
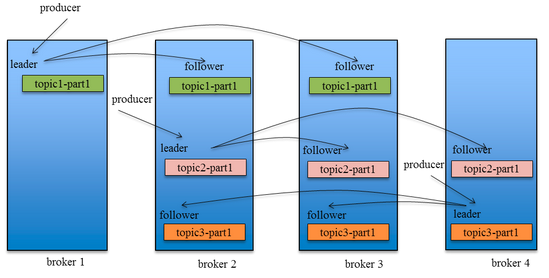
(2)Kafka中replica的均衡分布算法
Kafka中同一个topic中多个partition,以及每个partition的多个replica,在Kafka集群中的分布算法如下:
将所有Broker(假设共n个Broker)和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上
将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
(3)Kafka中partition的Leader Election选主算法
实际上,Leader Election算法非常多,比如ZooKeeper的Zab, Raft和Viewstamped Replication。而Kafka所使用的Leader Election算法更像微软的PacificA算法。
Kafka中的一些常用操作
(1)查看集群中的所有topic信息
1 | ./bin/kafka-topics.sh --list --zookeeper 192.168.65.239:2181 |
(2)查看集群中指定topic的详细信息
1 | ./bin/kafka-topics.sh --describe --zookeeper 192.168.65.239:2181 --topic wahaha-replicas |
其中,leader负责给定分区中所有的读和写的任务,分区将随即选取一个节点作为leader; replicas列出了所有当前分区中的副本节点,不论这些节点是否是leader或者是否处于激活状态,都会被列出来;isr是表示“在同步中”的副本节点的列表,是replicas列表的一个子集,包含了当前处于激活状态的节点,并且leader节点开头。
(3)给一个topic增加partition
1 | ./bin/kafka-topics.sh --zookeeper 192.168.65.239:2181 --alter --topic wahaha-replicas --partitions 3 |
备注:增加了分区或增加了broker节点,原有的数据并不会rebalance,可以使用Kafka自带的kafka-reassign-partitions.sh工具进行rebalance。
Kafka中消息发送端Producer的可靠性保证
发布端Producer可以通过acks参数来决定发布时的一些控制,具体如下:
acks=0 #producer不等待broker的acks。发送的消息可能丢失,但永远不会重发
acks=1 #leader不等待其他follower同步,leader直接写log然后发送acks给producer。这种情况下会有重发现象,可靠性比only once好点,但是仍然会丢消息。例如leader挂了了,但是其他replication还没同步完成
acks=all #leader等待所有follower同步完成才返回acks。消息可靠不丢失(丢了会重发),没收到ack会重发
备注:当acks=all的时候,就算你设置retries=0也依然会重发
Kafka集群的压力测试
Kafka集群的压力测试,可以使用Kafka自带的kafka-producer-perf-test.sh和kafka-consumer-perf-test.sh工具,使用方法如下:
(1)发布压力测试
1 | ./bin/kafka-producer-perf-test.sh --topic test-benchmark --num-records 100000000 --record-size 1024 --throughput 5000000 --producer-props bootstrap.servers=192.168.65.239:9092,192.168.65.239:9093 acks=all retries=2 linger.ms=1 |
(2)订阅压力测试
1 | ./bin/kafka-consumer-perf-test.sh --topic wahaha-replicas --batch-size 10000 --num-fetch-threads 2 --threads 10 --show-detailed-stats --group kafka.benchmark --messages 100000000 --broker-list 192.168.65.239:9092,192.168.65.239:9093 |
学习资料参考于:
http://www.infoq.com/cn/articles/kafka-analysis-part-1