logstash简介
Logstash事件处理流水线有三个阶段:输入->过滤器->输出。输入生成事件,过滤器修改它们,并将其输出到其他地方。
(1)输入,logstash的输入包括有文件、syslogn、redis、beats等
(2)过滤器,logstash的过滤器有grok、mutate、drop、clone以及geoip等
(3)输出,logstash的输出有ElasticSearch、文件、graphite等
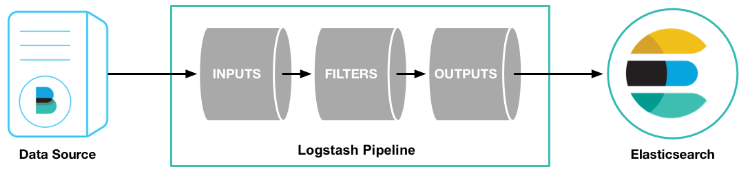
Logstash拥有丰富的输入,过滤器,编解码器和输出插件,要会使用各种插件,例如用来从文件读取数据源的插件logstash-input-file,将数据写入ES的插件logstash-output-elasticsearch。如果要查看当前logstash拥有的插件,可以执行./bin/logstash-plugin list命令查看。

logstash的配置与安装
前提声明:本次部署测试使用的是logstash-5.3.0
(1)下载logstash二进制部署包,并解压缩
(2)配置logstash
这里的配置logstash,是指配置logstash的input/filter/output等信息,建议在${LOGSTASH_HOME}下新建conf目录,然后创建一个任意名称的文件,假设此处新建一个nginx-error.conf的文件。配置内容形式如下:
1 | input { |
(3)启动logstash
执行命令./bin/logstash -f conf/nginx-error.conf即可
logstash的配置
logstash配置格式有四个需要注意的地方,分别是区域、数据类型、条件判断、字段引用。
(1)区域
logstash中,是用花括号{}来定义区域的,区域内可以使用插件。一个区域内可以定义多个插件。
(2)数据类型
布尔类型boolean,举例来说ssl_enable=>true
字符串类型string,举例来说name=>"Hello World"
数组Array,举例来说match=>["datetime","UNIX","ISO8601"]
哈希Hash,举例来说options=>{key1=>"value1",key2=>"value2"}
(3)条件判断
1 | if EXPRESSION { |
(4)字段引用
logstash的插件
logstash有四类插件,如下
inputs —— 输入的插件
codecs —— 解码的插件
filters —— 过滤的插件
outputs —— 输出的插件
可以在https://github.com/logstash-plugins查看一些logstash的插件
logstash各种插件的使用
(1)grok插件
grok用于将任意的文本进行结构化处理。grok是目前logstash中将混乱的非结构日志数据,进行结构化的最好方式。 用这个工具来解析syslog日志,apache或其他webserver日志,mysql日志的效果非常好。grok的基本语法是%{SYNTAX:SEMANTIC}。
其中SANTAX是用于匹配目标文本的模式的名称,SEMANTIC是我们用来自定义这个被匹配文本的字段名称。例如,%{IP:client_ip}就能够匹配IP地址,并将该字段命名为client_ip.
grok有120多种默认的模式,可以到https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns上查看。当然了我们也可以自定义自己的模式,自定义模式有两种方式,一种是类似(?<field_name>the pattern here),例如(?<queue_id>[0-9A-F]{10,11}),其中queue_id是自定义模式名,后面是正则匹配。另一种是在logstash的安装目录中创建一个patterns目录,然后在其中创建一些文件,文件内容类似于POSTFIX_QUEUEID [0-9A-F]{10,11},然后在grok插件中可以使用该模式。
如果数据源的格式不统一,我们可以在grok中定义多个正则规则,举例如下:
1 | match => [ |
logstash 会按照这个定义次序依次尝试匹配,到匹配成功为止。
(2)ruby插件
如果你稍微懂那么一点点Ruby语法的话,filters/ruby 插件将会是一个非常有用的工具。 比如你需要稍微修改一下 LogStash::Event 对象,但是又不打算为此写一个完整的插件,用ruby插件绝对感觉良好。使用ruby插件可以对event执行ruby语句,举例来说:
1 | filter { |
(3)mutate插件
mutate插件是Logstash的另一个重要插件。它提供了丰富的基础类型数据处理能力,包括类型转换、字符串处理和字段处理等。
filter/mutate插件的使用
参见http://www.mobile-open.com/2016/940848.html
logstash的最佳实践
(1)./bin/logstash -t -f ./conf/logstash.conf ##测试logstash的配置文件是否正确,不会直接启动logstash
(2)logstash是保存有发布进度状态的,当重启logstash,logstash会继续之前的进度继续发布数据,而不会丢失哦
logstash闲杂知识点
(1)最简单的logstash配置
1 | input { |
备注:表示从从标准输入中读取数据,然后从标准输出中输出数据
(2)logstash的helloworld
1 | ./bin/logstash -e "input{stdin{}} output{stdout{codec=>rubydebug}}" |
(3)清空logstash的传输进度是清空${LOGSTASH_HOME}/data目录中的内容即可?
(4)如果logstash的grok插件解析字段失败,输出的event中包含_grokparsefailure的tag,我们可以在kibana上搜索该字段,如果发现有_grokparsefailure关键词,那么说明有些日志解析失败了。