zookeeper简介
ZooKeeper是一个开放源码的分布式协调服务,由知名互联网公司雅虎创建,是Google Chubby的开源实现。ZooKeeper致力于提供一个高性能、高可用、且具有严格的顺序访问控制能力的分布式协调服务。分布式应用可以基于ZooKeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁以及分布式队列等功能。
zookeeper的基本概念
(1)节点角色
Leader —— 是整个zookeeper集群的核心
Follower ——
Observer ——
(2)会话Session
会话Session是指客户端和zookeeper服务器的连接,客户端与服务器建立一个TCP的长连接来维持一个Session。客户端启动时,会与服务器建立一个TCP连接。
(3)watcher
zookeeper允许用户在指定节点上注册一些watcher,当该数据节点发生变化时,zookeeper服务器会把这个变化通知给感兴趣的客户端。
(4)ACL权限控制
zookeeper采用ACL策略来进行权限控制,例如,
CREATE ## 创建子节点的权限
READ ## 获取节点数据和子节点列表的权限
WRITE ## 更新节点数据的权限
DELETE ## 删除子节点的权限
ADMIN ## 设置节点ACL的权限
(5)snapshot
zookeeper集群中的所有节点以及数据都会存放到内存中,形成一棵树的数据结构。zookeeper集群会定期地把内存中的数据dump到本地磁盘上,称为快照snapshot。
(6)znode
zookeeper中每一个数据节点都称为一个zonde,注意这里的节点并非部署zookeeper的服务器节点哦,而是指zookeeper数据存储结构中节点啦。
(7)zxid
zookeeper状态的每一次改变,都对应着一个递增的Transaction id,该id就称为zxid。由于zxid的递增性质,如果zxid1小于zxid2,那么zxid1肯定先于zxid2发生。创建任意节点、更新任意节点的数据或者删除任意节点,都会导致zookeeper状态发生改变,从而导致zxid的值增加。
zookeeper的znode节点类型
(1)persistent节点
persistent节点不和特定的session绑定,不会随着创建该节点的session的结束而消失,而是一直存在,除非该节点被显式删除。
(2)ephemeral节点
ephemeral节点是临时性的,如果创建该节点的session结束了,该节点就会被自动删除。ephemeral节点不能拥有子节点。虽然ephemeral节点与创建它的session绑定,但只要该该节点没有被删除,其他session就可以读写该节点中关联的数据。使用-e参数指定创建ephemeral节点。
(3)sequence节点
严格的说,sequence并非节点类型中的一种。sequence节点既可以是ephemeral的,也可以是persistent的。创建sequence节点时,ZooKeeper server会在指定的节点名称后加上一个数字序列,该数字序列是递增的。因此可以多次创建相同的sequence节点,而得到不同的节点。使用-s参数指定创建sequence节点。
zookeeper的数据结构模型
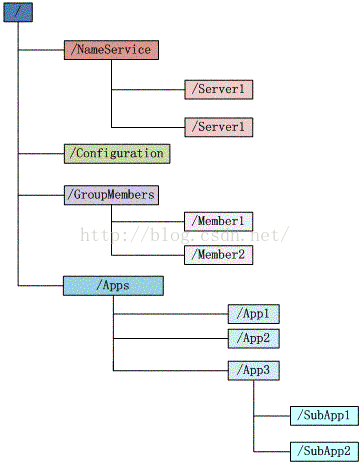
zookeeper的数据结构模型就形如上图,图中的每个节点称为一个znode,每个znode由3部分组成:
(1)stat
此为状态信息,描述该znode的版本,权限等信息。stat详细参数如下:
| 属性名 | 含义 | 备注 |
|---|---|---|
| czxid | 节点创建时的zxid(Create) | |
| mzxid | 节点最新一次更新发生时的zxid(Mofify) | 只表示本节点的修改,若子节点有修改,不会影响到mzxid |
| pzxid | 是与该节点或其子节点的最近一次创建/删除时的zxid | 只与本节点/该节点的子节点有关,与孙子节点无关 |
| ctime | 节点创建时的时间戳 | |
| mtime | 节点最新一次更新发生时的时间戳 | |
| dataVersion | 节点数据的更新次数 | |
| cversion | 其子节点的更新次数 | |
| aclVersion | 节点ACL(授权信息)的更新次数 | |
| ephemeralOwner | 如果该节点为ephemeral节点,ephemeralOwner值表示与该节点绑定的session id;如果该节点不是ephemeral节点,ephemeralOwner值为0 | |
| dataLength | 节点数据的字节数 | |
| numChildren | 子节点个数 |
(2)data
与该znode关联的数据。
(3)children
该znode下的子节点。
zookeeper架构及读写过程
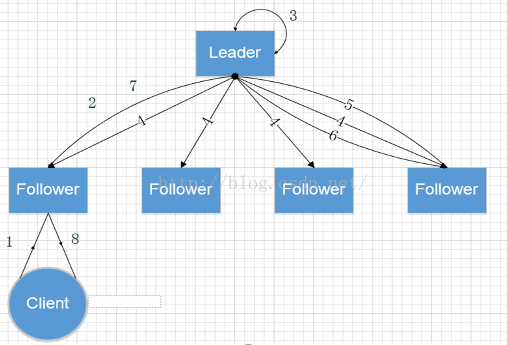
(1)客户端提交请求
(2)follower接受到请求,转发给leader
(3,4)leader开始本地写,并且下发写操作到所有follower
(5)某一个follower收到propose,开始写事务日志,此时并没有真正更新到内存中
(6)写完日志后返回ack给leader,当leader收到加自己超过一半的机器的回复后,返回commit
(7)所有follwer开始更新内存树。leader告诉发写请求的follower,follower再通知client写成功
zookeeper的应用场景
名字服务(Name Service)
配置管理(Configuration Management)
集群管理
共享锁(Locks)
队列管理
zookeeper集群的配置和搭建
搭建测试一:单节点zookeeper集群的配置和搭建
(1)下载zookeeper二进制安装文件
在http://zookeeper.apache.org/releases.html页面下载zookeeper稳定的版本(本次部署测试用的是zookeeper-3.4.10)。然后解压即可。
(2)配置zookeeper
在${ZOOKEEPER_HOME}/conf目录中新建zoo.cfg配置文件,并增加如下内容:
tickTime=2000
dataDir=/var/lib/zookeeper #存储zookeeper内存中数据的快照
clientPort=2181 #zookeeper服务监听的端口
zookeeper服务启动时,默认读取的是conf/zoo.cfg配置文件。
zookeeper中的数据在内存和本地磁盘中都存在,提供服务时,使用的是内存中的数据。同时zookeeper也会将内存中的快照存储到本地磁盘,当zookeeper重启或宕掉时,可以加载被持久化的快照来恢复服务。
(3)启动zookeeper
1 | ./bin/zkServer.sh start |
(4)测试连接zookeeper
1 | ./bin/zkCli.sh -server 192.168.65.239:2182 |
或者
1 | telnet 192.168.65.239 2182 ##连接上之后,执行stat命令查看zookeeper状态 |
或者
1 | echo stat | nc 192.168.65.239 2182 |
或者
1 | ./bin/zkServer.sh status |
搭建测试二:多节点的复制zookeeper集群的配置和搭建(伪集群)
(1)下载zookeeper二进制安装文件
在http://zookeeper.apache.org/releases.html页面下载zookeeper稳定的版本(本次部署测试用的是zookeeper-3.4.10)。解压之后,可以将目录名称命名为zookeeper-node-1。
(2)配置zookeeper zookeeper-node-1
在${ZOOKEEPER_HOME}/conf目录中新建zoo.cfg配置文件,并增加如下内容:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/prod/zookeeper-cluster/zookeeper-node-1/data #存储zookeeper内存中数据的快照
clientPort=2181 #zookeeper服务监听的端口
# 配置zookeeper集群中的所有节点的ip和port信息
server.1=192.168.65.239:2688:3688
server.2=192.168.65.239:2788:3788
server.3=192.168.65.239:2888:3888
备注:
server.id=host:port1:port2
id —— 是zookeeper集群中各节点的编号,id是阿拉伯数字
host —— host是主机的ip或机器名
port1 —— 第一个port是follower节点和Leader节点的通信端口
port2 —— 第二个port是Leader重新选举时的投票通信端口
(3)配置zookeeper节点的server.id
在${ZOOKEEPER_HOME}/conf/zoo.cfg中dataDir配置指定的目录(在本例中是/root/prod/zookeeper-cluster/zookeeper-node-1/data )中,新建一个myid文件,写入一个阿拉伯数字,代表本zookeeper节点在zookeeper集群中的编号。假定此处设置为1。
(4)新建其他节点的程序环境
A)配置zookeeper-node-2
1 | cp -r zookeeper-node-1 zookeeper-node-2 |
修改zookeeper-node-2/conf/zoo.cfg如下:
dataDir=/root/prod/zookeeper-cluster/zookeeper-node-2/data
clientPort=2182
修改/root/prod/zookeeper-cluster/zookeeper-node-2/data/myid,设置值为2。
B)配置zookeeper-node-3
1 | cp -r zookeeper-node-1 zookeeper-node-3 |
修改zookeeper-node-3/conf/zoo.cfg如下:
dataDir=/root/prod/zookeeper-cluster/zookeeper-node-3/data
clientPort=2183
修改/root/prod/zookeeper-cluster/zookeeper-node-3/data/myid,设置值为3。
(5)启动zookeeper各个节点
1 | cd /root/prod/zookeeper-cluster/zookeeper-node-1 && ./bin/zkServer.sh start |
(6)测试连接zookeeper
1 | ./bin/zkCli.sh -server 192.168.65.239:2181 |
备注:本次配置的伪zookeeper集群,如果有多台物理服务器,集群的配置方式和伪集群的配置差不多。
zookeeper的客户端
ZooKeeper的客户端有如下几种:
(1)使用./bin/zkCli.sh
1 | ./bin/zkCli.sh -server ip:port |
常用的命令有ls/stat/get/create/set/get/delete/rmr。
(2)使用zookeeper JAVA api
使用zookeeper JAVA API来编程。
(3)开源客户端ZkClient
ZkClient是Github上一个开源的zookeeper客户端。ZkClient在zookeeper原生API接口之上进行了包装,是一个更加易用的zookeeper客户端。
(4)开源客户端Curator
Curator是Netflix公司开源的一套ZooKeeper客户端框架,Curator解决了很多的ZooKeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher等,实现了Fluent风格的API接口,目前已经成为Apache的顶级项目,是全世界范围内使用最广泛的ZooKeeper客户端之一。
zookeeper的一些重要配置参数
(1)tickTime
tickTime用于配置zookeeper中最小时间单元的长度,单位是毫秒ms。zookeeper中很多的时间配置都是用tickTime的倍数来表示,例如initLimit=5表示5倍的tickTime。
(2)initLimit
Follower节点在启动时,会与Leader节点建立连接,并同步Leader的数据,这个需要一定的时间。initLimit就是用来限制最大允许的同步时间。如果Follower节点从Leader同步数据的时间超过了initLimit设置的时间,那么就会同步失败。一般我们使用默认值就可以了,也就是initLimit=10。
(3)dataLogDir
用来配置存储zookeeper服务器的事务日志文件的路径位置。如果没有配置dataLogDir,zookeeper的事务日志文件默认和数据快照存在在一起(也就是dataDir配置的目录)。我们尽量将事务日志文件和数据快照存在在不同的地方,最好是存储到不同的磁盘上。
(4)electionAlg
用来配置zookeeper Leader选举的算法,但是从3.4.0,zookeeper只保留了fast-leader算法,因此这个参数没有什么作用了。
(5)syncLimit
用来设置Leader和Follower节点之间进行心跳检测的最大延迟时间。如果Leader节点在syncLimit设定的时间内没有收到Follower节点的心跳包,那么Leader节点会认为该Follower节点已经挂掉了。一般我们使用默认值就可以了,也就是syncLimit=5。
zookeeper的4字命令
zookeeper支持像conf/stat这样四个字母左右组成的命令,我们称之为“4字命令”。执行4字命令有两种方式:
(1)使用telnet host port登录zookeeper实例,然后执行stat/conf等这样的命令
(2)使用echo stat | nc host port
下面列举一些常用的四字命令:
stat —— 用于输出zookeeper集群的统计信息
conf —— 列举出zookeeper的一些配置信息
cons —— 列举出所有连接的客户端的详情
crst —— 用于重置所有客户端的连接统计信息
dump —— 用于输出当前集群所有会话信息
ruok —— 用于输出当前zookeeper集群是否正在运行
mntr —— 用于输出比stat更详细的统计信息
还有其他的一些4字命令,不一一列出来。
zookeeper监控平台的搭建和使用
(1)exhibitor
netflix公司开发的,可以通过exhibitor来管理zookeeper集群,例如重启zookeeper节点、日志清除功能等。
(2)zabbix
用来监控zookeeper节点所在服务器的CPU/MEM/NET等信息。
(3)ambari监控zookeeper
zookeeper集群的最佳实践
(1)一个具有3个节点的zookeeper集群可以支持12-13w QPS的压力
(2)zookeeper集群中,如果有超过一半节点是正常的,那么整个zookeeper集群就可以对外提供服务。否则集群停止对外服务。所以zookeeper集群最好使用奇数个节点,比如3,5,7个节点。比如一个集群有4个节点,因为超过半数才正常,所有该集群也只允许一个节点挂掉。
(3)使用jps命令可以查看zookeeper的进程名,进程名为QuorumPeerMain
学习资料参考于:
https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
http://coolxing.iteye.com/blog/1871328