ElasticSearch对外API
ElasticSearch对外暴露两种形式的API,一种是JAVA API,另一种是HTTP Restful API。具体说明如下:
(1)JAVA API
JAVA API又分为Node Client和Transport Client两种,两种Java客户端都通过9300端口与集群交互,使用ElasticSearch传输协议(Elasticsearch Transport Protocol)进行通信。集群中的节点之间也通过9300端口进行通信。如果此端口未开放,你的节点将不能组成集群。另种JAVA API具体说明如下:
A)节点客户端Node Client
节点客户端以无数据节点(none data node)身份加入集群,换言之,它自己不存储任何数据,但是它知道数据在集群中的具体位置,并且能够直接转发请求到对应的节点上。
B)传输客户端Transport Client
这个更轻量的传输客户端能够发送请求到远程集群。它自己不加入集群,只是简单转发请求给集群中的节点。
(2)HTTP Restful API
基于HTTP协议,以JSON为数据交互格式的RESTful API,通过9200端口的与Elasticsearch进行通信。ElasticSearch提供的一些HTTP RESTful API:
1 | _cat API —— 格式化输出API |
ElasticSearch的一些常见操作
使用申明:v参数表示打印详细输出;pretty参数表示格式化的样式输出,输出结果更直观。
(1)查看集群的健康状态
1 | GET /_cat/health?v |
备注:ElasticSearch集群有三种健康状态,分别是green,yellow以及red,如下:
green表示集群中所有的主分片和副本都是正常的,处于活动状态。
yellow表示集群现中所有的主分片是正常的,处于活动状态。但不是所有的replica处在活动状态。
red表示集群中不是所有的主分片是正常的,处于活动状态
(2)查看集群的所有节点
1 | GET /_cat/nodes?v |
(3)查看所有的索引
1 | GET /_cat/indices?v |
(4)在索引bank的account类型中,查找id为1的文档
1 | GET http://192.168.65.239:9200/bank/account/1?pretty |
(5)查找一个索引指定类型的所有的文档信息,默认显示10个,加载size参数可以指定返回大小
1 | GET http://192.168.65.239:9200/bank/account/_search?pretty |
(6)查看last_name属性为Smith的账户信息
1 | GET /bank/account/_search?q=last_name:Smith |
(7)使用DSL方式查询
1 | GET /bank/account/_search |
(8)删除索引中某一个文档
1 | DELETE /bank/account/1 |
(9)删除一个索引
1 | DELETE /bank |
ElasticSearch HTTP REST API的使用
ElasticSearch REST API的使用形式有两种,一种是将查询参数拼接到url里面,另一种是将查询参数放到-d选项中。
(1)请求参数方式(Query String)
举例来说,
1 | curl -XGET 'localhost:9200/bank/_search?q=*&pretty' |
(2)请求体方式(Query DSL)
举例来说,
1 | curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' |
(3)查询中的term与match
term表示精确匹配,即我们的搜索词不会被切词。举例来说,如果我们搜索的关键词是“中国北京”,那么ES建立的倒排索引的term中,必须有“中国北京 ”的文档才会被检索出来。
而如果我们使用match来搜索时,会先对搜索词进行切词。举例来说,如果我们搜索的关键词是“中国北京”,那么先会被切分为“中国”和“北京”两个词,当匹配到其中任何一个的文档都会被检索出来。
学习资料参考于:http://www.cnblogs.com/muniaofeiyu/p/5616316.html
(4)search API输出查询结果的数据结构
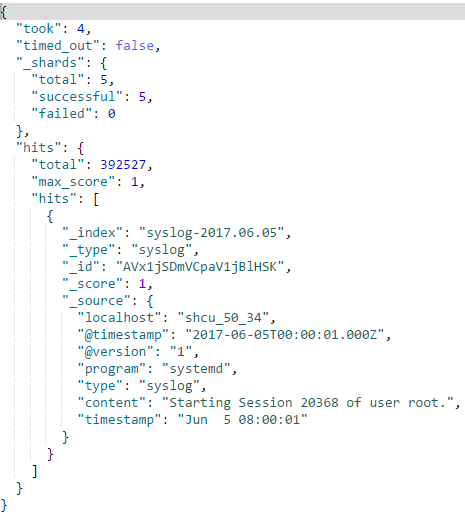
主要字段说明如下:
took ## 是查询花费的时间,毫秒单位
time_out ## 标识查询是否超时
_shards ## 描述了查询分片的信息,查询了多少个分片、成功的分片数量、失败的分片数量等
hits ## 搜索的结果,total是全部的满足的文档数目,hits是返回的实际数目(默认是10)
_score ## 文档的分数信息,与排名相关度有关
ElasticSearch中的映射Mapping
在ES中,索引具有一定的数据结构,称为映射(mapping)或者模式定义(schema definition)。一个映射定义了索引有哪些字段,每个字段的数据类型以及字段被Elasticsearch处理的方式等。
(1)ES支持的字段数据类型
字符串类:string
整型类:byte、short、integer、long
浮点类:float、double
布尔类:boolean
日期类:date
(2)ES的动态映射
当我们向ES插入文档时,当文档中包含一个之前不存在的字段,Elasticsearch将使用动态映射猜测字段类型,动态映射的规则如下:
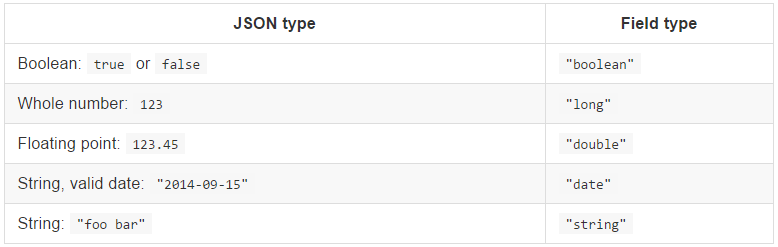
(3)ES字段分词相关的配置
当我们定义mapping时,可以为某个字段指定index和analyzer属性。
A)index
index可以被设置为如下三个字段(缺省为analyzed):
analyzed:表示该字段会被分词,然后被索引。例如某个字段的值是“中国”,那么会被分为“中”、“国”。我们可以通过“中国”、“中”、“国”都可以搜索到该文档
not_analyzed:表示该字段不会被分词,例如“中国”,只能通过关键字“中国”搜索到
no:表示不为该字段建索引,也就是说该字段不能根据关键词被搜索到
备注:其他简单类型(long、double、date等)也接受index参数,但相应的值只能是no和not_analyzed,它们的值不能被分析。
B)analyzer
使用analyzer参数用来指定使用哪一种分析器来分词。默认的Elasticsearch使用standard分析器,但可以通过指定一个内建的分析器来更改它,例如whitespace、simple或english。
(4)查看某个索引的指定类型的mapping
1 | curl -XGET 'http://10.19.120.93:9200/log-error-2017.06.05/_mapping/log-error?pretty' |
ElasticSearch中的创建索引以及索引初始化
当我们往ElasticSearch集群中一个还不存在的索引中添加一个文档时,API会自动创建一个索引,该索引使用默认设置,且字段属性通过动态映射来决定的。在ES中通过设置action.auto_create_index: false来禁止自动创建索引。
其实,我们可以通过API手动的创建索引,并配置索引的Mapping,命令的格式为:
1 | PUT /my_index |
Python的ES API第三方库
Python封装好的API有两个库,一个是elasticsearch-py,一个是elasticsearch-dsl-py。其中elasticsearch-py是低级库,和HTTP REST API的形式类似,而elasticsearch-dsl-py是基于elasticsearch-py,对api做了更好的封装。
备注:elasticsearch-dsl-py的开发文档有点晦涩,暂时就使用elasticsearch-py低级python库了。