DPDK技术简介
Intel® DPDK全称Intel Data Plane Development Kit,是Intel提供的数据平面开发工具集,为Intel Architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,它不同于Linux系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。目前已经验证可以运行在大多数Linux操作系统上,包括FreeBSD 9.2、Fedora release 18、Ubuntu 12.04 LTS、RedHat Enterprise Linux 6.3和SUSE Enterprise Linux 11 SP2等。DPDK使用了BSD License,极大的方便了企业在其基础上来实现自己的协议栈或者应用。
需要强调的是,DPDK应用程序是运行在用户空间上利用自身提供的数据平面库来收发数据包,绕过了Linux内核协议栈对数据包处理过程。Linux内核将DPDK应用程序看作是一个普通的用户态进程,包括它的编译、连接和加载方式和普通程序没有什么两样。DPDK程序启动后只能有一个主线程,然后创建一些子线程并绑定到指定CPU核心上运行。
DPDK核心组件由一系列库函数和驱动组成,为高性能数据包处理提供基础操作。内核态模块主要实现轮询模式的网卡驱动和接口,并提供PCI设备的初始化工作;用户态模块则提供大量给用户直接调用的函数。DPDK本身是一些库函数和驱动,使用了DPDK库函数的应用程序则称为“DPDK应用程序”。
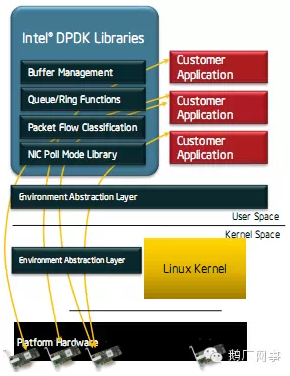
直白地说,DPDK绕过了Linux内核协议栈,处在用户空间下的DPDK应用程序直接使用硬件驱动的接口来收发报文。类似于DPDK,PF_RING和Netmap等工具也实现了类似的功能。有了DPDK,就可以让服务器的数据包转发或数据包处理能力大大地提升了。
在dpdk中有一个igb_uio模块,是关于网卡的驱动模块。
DPVS技术简介
DPVS全称为“DPDK-LVS”,来源iqiyi的开源项目。DPVS是基于DPDK的高性能第4层负载均衡器,且基于alibaba/LVS修改而来。简单来说,DPDK+LVS=DPVS。从目前的测试数据来看,DPVS的性能优于LVS。架构图如下:
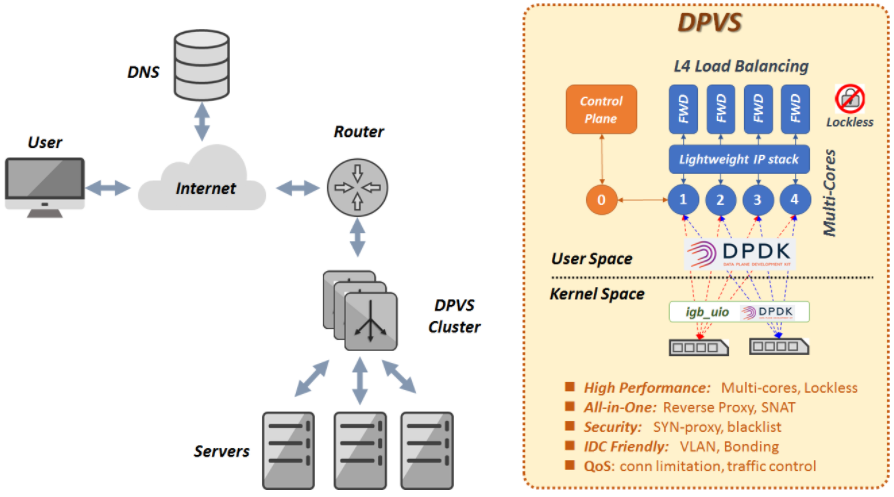
我的理解是,DPVS使用DPDK的高性能转发技术,直接从硬件驱动的接口中读取数据,绕过了Linux协议栈,然后在操作系统的用户空间中把内核LVS的功能重新实现了一遍。
如下是DPVS项目的所有模块:
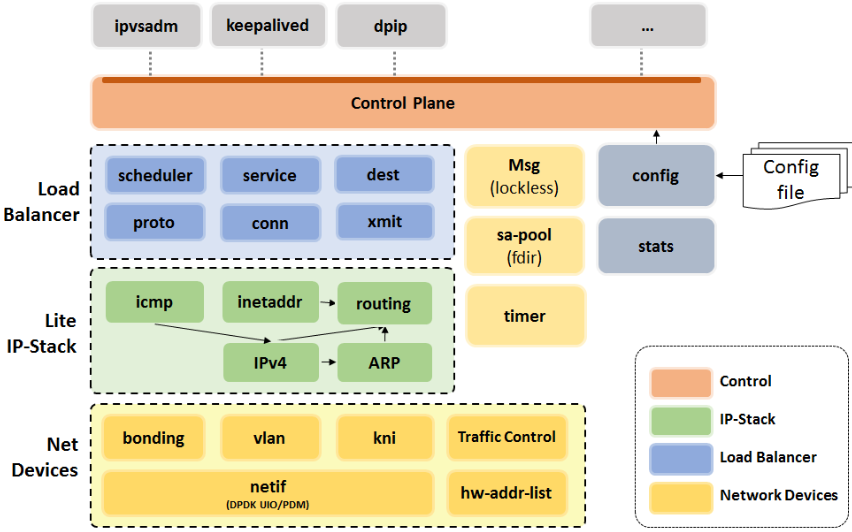
其中实现了一个用户空间的轻型IP协议栈(功能类似于系统空间的内核IP协议栈)。
dpdk和linux内核协议栈处理数据的关系
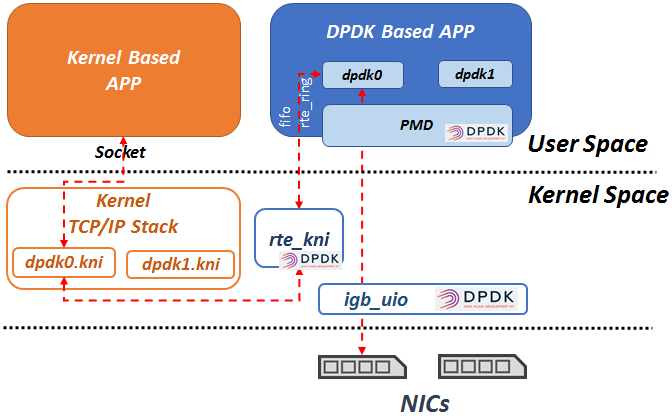
dpdk接管了linux部分网卡,直接接收和发送数据包。dpdk会在操作系统内核层面设置KNI网卡,dpdk将不想处理的数据包,如vrrp、ospf或sshd,通过DPDK rte_kni模块转发给系统协议栈的KNI网卡,从而走Linux系统的协议栈来处理数据包。需要注意的是,dpdk0和dpdk0.kni网卡对应,dpdk1和dpdk1.kni网卡对应。即dpdk0将不想处理的数据包转发给dpdk0.kni,dpdk1将不想处理的数据包转发给dpdk1.kni。
我们使用ip addr show命令查看到的是linux系统层面的网卡NICs,使用dpip addr show看到的DPDK内部的网卡NICs。
DPDK与Linux内核处理数据包的对比

DPDK拦截中断,不触发后续中断流程,并绕过协议栈,通过UIO技术将网卡收到的报文拷贝到应用层处理,报文不再经过内核协议栈。减少了中断,DPDK的包全部在用户控件使用内存池管理,内核控件与用户空间的内存交互不用进行拷贝,只做控制权转移,减少报文拷贝过程,提高报文的转发效率。
DPDK核心技术如下:
kernel bypass,通过UIO技术将报文拷贝到应用空间处理
通过大页内存,降低cache miss,提高命中率,进而cpu访问速度
通过cpu亲和性,绑定网卡和线程到固定的core,减少cpu任务切换
通过无锁队列,减少资源竞争
DPDK-LVS的部署实践
目前DPVS支持NAT、Tunnel、DR、FULLNAT以及SNAT的模式。其中NAT、Tunnel、DR、FULLNAT可以用来部署LVS集群,即作为4层负载均衡设备,其中SNAT模式用来搭建NAT集群。
对于LVS集群部署上来说,目前业界比较多采用的是FULLNAT + OSPF/ECMP(一致性hash)模式部署,这种模式适合大规模的集群化部署,也能够实现单机LVS故障时的平滑迁移。
DPDK-LVS的性能对比数据
(1)普通LVS的DR模式的性能数据
10Gbps+的HTTP流量
1000w+ pps的转发量
(2)dpvs/lvs/maglev性能对比
从“数据包转发速率”这一项核心指标上来说:
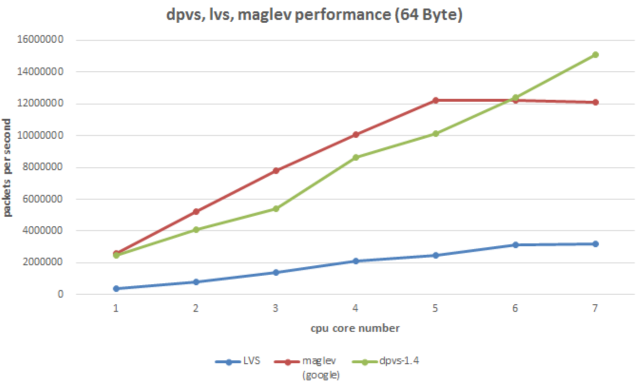
简单概括下,基于DPDK的DPVS相比于内核LVS要高5倍左右的性能。
(3)附上一张百度BGW性能数据图

DPDK-LVS性能高效的主要因素
(1)Kernel ByPass,内核旁路,也就是绕过内核,直接在用户态获取网卡数据,读取网卡数据采用轮询机制,而不是传统的依靠中断。当前Linux操作系统都是通过中断方式通知CPU来收发数据包,我们假定网卡每收到10个据包触发一次软中断,一个CPU核心每秒最多处理2w次中断,那么当一个核每秒收到20w个包时就占用了100%,此刻它没做其它任何操作。DPDK针对Intel网卡实现了基于轮询方式的PMD(Poll Mode Drivers)驱动,该驱动由API、用户空间运行的驱动程序构成,该驱动使用无中断方式直接操作网卡的接收和发送队列(除了链路状态通知仍必须采用中断方式以外)。目前PMD驱动支持Intel的大部分1G、10G和40G的网卡。PMD驱动从网卡上接收到数据包后,会直接通过DMA方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理数据包,这个过程非常简洁。如果要是让Linux来处理收包过程,首先网卡通过中断方式通知协议栈对数据包进行处理,协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否本机的socket,满足条件则会将数据包拷贝一份向上递交给用户socket来处理,不仅处理路径冗长,还需要从内核到应用层的一次拷贝过程。总之,内核旁路的好处是绕过中断,绕过复杂的内核协议栈,DMA直接读取内存数据等。
(2)可以利用网卡多队列以及CPU亲和性设置,即可以绑核。
(3)内核是一个通用平台,为了安全性设计,会有很多锁的竞争机制,而DPVS做到lockless,即无锁竞争。
(4)使用大页内存,这个需要看看计算机组成原理。
LVS/DPVS FULLNAT模式下用户真实IP获取与TOA/UOA模块
(1)LVS/DPVS FULLNAT模式下获取用户真实IP困难
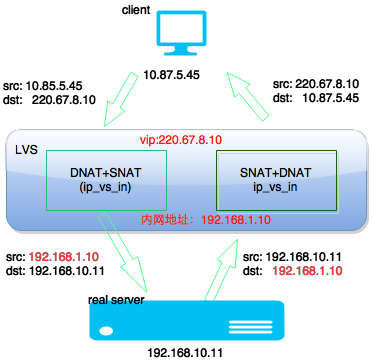
从上图可以发现FULLNAT模式一个问题,RS无法获得用户IP。
(2)阿里开发的TOA内核模块以及百度开发的TTM内核模块
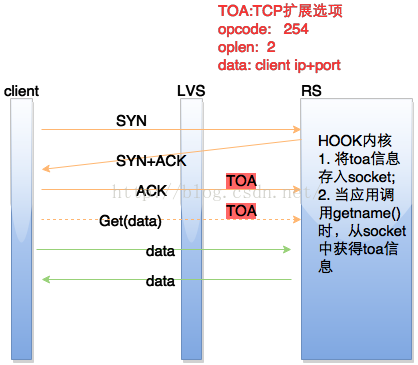
阿里巴巴是通过开发一个叫TOA的内核模块来解决这个问题的。TOA主要原理是将用户真实IP地址放到了TCP Option字段里面,并带给后端RS,RS收到后保存在socket的结构体里并通过TOA内核模块Hook了getname函数,这样当应用程序调用getname获取远端地址时,返回的是保存在socket的TCP Option的IP。百度的BVS是通过一个叫TTM的内核模块来实现的,其实现方式跟TOA基本一样,只是没有开源。
TOA的原理图如下:
其他闲杂知识
(1)DPDK启动后,会接管linux的上某些网卡,如eth0,eth1等。
(2)DPVS支持高可用性架构,目前有两种HA架构,一种是OSPF/ECMP,一种是主备模式。OSPF/ECMP模式需要quagga路由器模拟软件。主备模式需要用到keepalived。
(3)DPVS采用Master/Worker的工作模型,其中每个Worker绑定到一个CPU核心上。
学习资料参考于:
https://dpdk.org/
https://github.com/iqiyi/dpvs
https://mp.weixin.qq.com/s?__biz=MzA3ODgyNzcwMw==&mid=202113096&idx=1&sn=7ce616f596c529890dfd475ce8d31858&scene=4##
http://www.infoq.com/cn/presentations/implementation-of-high-performance-load-equalizer-based-on-dpdk#downloadPdf
https://tech.meituan.com/MGW.html
https://blog.csdn.net/mumumuwudi/article/details/47064281