InnoDB引擎的存储结构
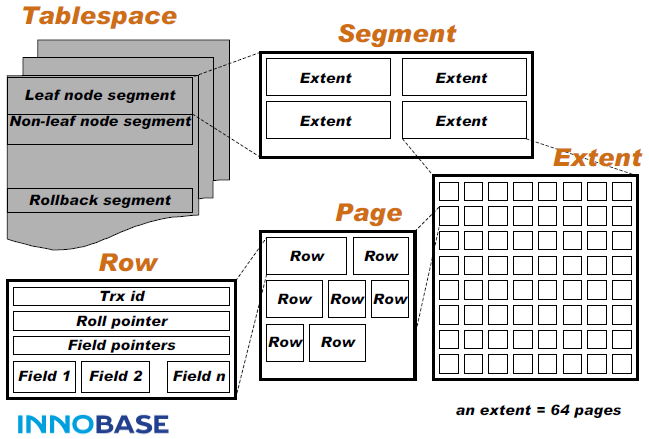
InnoDB的存储结构是有表空间TableSpace、段Segment、区Extent、页Page、行Row组成。数据库中所有记录可以放到一个表空间中(称为共享表空间),也可以每一张表放到不同的表空间中(称为独立表空间)。
在InnoDB中每个页Page的大小是16KB,页Page是InnoDB磁盘管理的最小单位。
行Row就是我们一条的数据记录。
InnoDB聚集索引
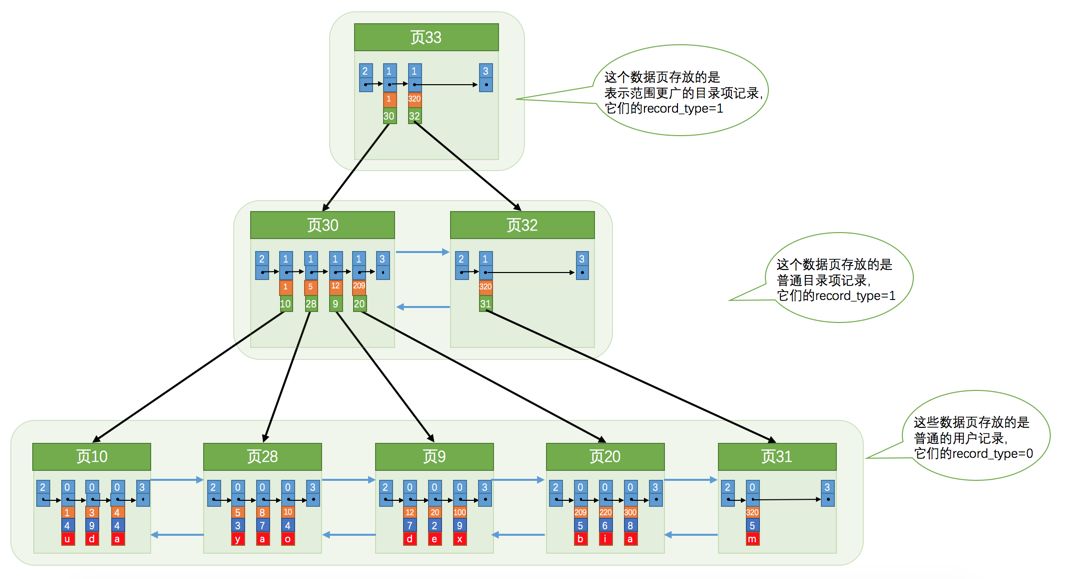
如上就是InonDB的聚集索引,它有如下的特点:
(1)聚集索引是一个B+树的数据结构,B+树每个节点就是InnoDB中一个页Page
(2)B+数的叶子节点存储的是一张表的完整数据记录。B+树的非叶子节点存储的是为了快速检索数据的目录数据,非实际的数据记录
(3)所有页Page内的记录是按照主键的大小顺序排成一个单向链表
(4)每一层的所有页Page按主键大小顺序排成一个双向链表
我们把具有如上特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的去创建,InnoDB存储引擎会自动地为我们在主键上创建聚簇索引。如果表没有主键,InnoDB会选择一个非NULL且唯一索引作为聚集索引。若主键和非NULL且唯一索引都不存在,InnoDB将会自动增加一个6字节(48位)的整数列,被叫做ROWID,聚集数据将在这个隐藏列上创建,需要注意的是,ROWID既不能通过任何查询获取到也不能做像基于行复制的任何内部操作,是看不到的。
另外有趣的一点是,在InnoDB存储引擎中,聚簇索引就是数据的存储方式(一张表所有的数据记录都存储在了叶子节点),也就是所谓的索引即数据。
简单来说,InnoDB中每一种表都自动有一个聚集索引,而该聚集索引也完整的包括了该表的所有数据记录,而并非是一个快速查找数据的目录而已。
InnoDB索引的一些概念
聚集索引(主键索引)
聚集索引,也成为主键索引。其他的索引统称为非聚集索引。
普通索引
普通索引,也称二级索引,也是一个B+树的结构,但是普通索引有如下几点不同:
(1)普通索引需要人为显式地在数据表中某一列上创建
(2)在数据表某字段上创建普通索引,索引中各种排序链表,是按照该字段的值进行排序
(3)普通索引的B+树的叶子节点对应页Page的记录,就不是数据表中完整的记录,只包含被索引列的值和主键值,而记录中其他字段是不存储的
因此当我们执行一条select语句用到一个普通索引时,会在普通索引的B+树结构中,找到对应被索引列的值和主键值。然后再通过主键值,去聚集索引中查找到最终的完整数据记录。这个过程应该叫回表查询。
联合索引
它是普通索引中的一种。
联合索引,也称复合索引或组合索引,是我们在数据表的多个列上创建一个索引。如在f1和f2列上创建联合索引,那么联合索引对应的B+树中链表排序,是先根据f1进行排序,若f1相同再根据f2进行排序。当我们执行一条select语句用到一个组合索引时,会在组合索引的B+树结构中,也是先找到对应多个被索引列的值和主键值。然后再通过主键值,去聚集索引中查找到最终的完整数据记录。
举例来说,我们在表myTable上的三个字段(vc_Name,vc_City,i_Age) 创建一个组合索引里如下:
1 | ALTER TABLE `myTable` ADD INDEX `name_city_age` (vc_Name(10),vc_City,i_Age); |
这就相当于分别建立了三个组合索引如下:
vc_Name,vc_City,i_Age
vc_Name,vc_City
vc_Name
为什么没有vc_City,i_Age等这样的组合索引呢?这是因为MySQL组合索引“最左前缀”的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引。
因此若执行SELECT * FROM myTable WHREE vc_Name=”erquan” AND vc_City=”郑州”;SQL语句,是会用到上面的组合索引。若执行SELECT * FROM myTable WHREE i_Age=20 AND vc_City=”郑州”;SQL语句是不会用到上面的组合索引。
前缀索引
它是普通索引中的一种。当要索引的列字符很长时,索引则会很大且变慢,而我们又需要在此字段上创建索引来提供查询效率,这时可以在该字段的前N个字符上创建索引,节约索引空间,从而提高索引效率,这也成为前缀索引。
假设有如下一个test表:
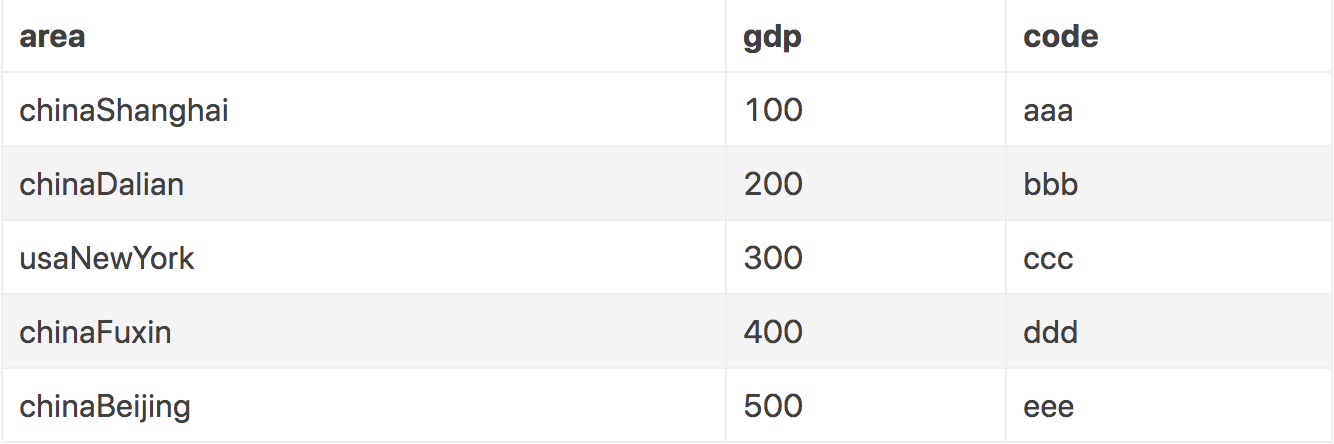
执行alter table test add index(area(5));SQL语句就可以在在area字段的前5个字符上创建了前缀索引。创建前缀索引时,一定要注意索引长度和重复度的权衡选择。
覆盖索引
并非一种索引哦。
若我们只想查询数据表的某些列,并非是记录的所有列,且要查询的列正好包含在索引列中,也就是索引的B+树的叶子节点中已经包含了这些列的值,那么不用在透过主键去聚集索引中去在查找一遍啦,直接返回就好了。这种情形也叫“覆盖索引”。
比如select income from user where imcome>40;时,因income字段上建立了索引,索引文件中已经有income字段的内容了,这时就不用拿着主键再去聚集索引中做回表查询啦。
其他闲杂知识
(1)一般说来,在InnoDB的索引B+树中,最多需要四层就可以满足啦
(2)上面说的都是InnoDB的存储结构以及索引原理,不同的存储引擎会表现的稍有不同。如MyISAM的聚集索引B+树的叶子节点,只存储了主键值和行号。数据查询会通过聚集索引找到主键值和行号,然后再通过行号(也就物理位置的偏移量)找到完整的数据记录。
学习资料参考于:
我们都是小青蛙的《InnoDB记录存储结构》
我们都是小青蛙的《InnoDB数据页结构》
我们都是小青蛙的《MySQL的索引》
我们都是小青蛙的《MySQL的索引(中)》