Redis简介
Redis是一个key-value的非关系型数据库(NoSQL),现在在各种系统中的使用越来越多,大部分情况下是因为其高性能的特性,被当做缓存使用。Redis应用广泛,尤其是被作为缓存使用,Redis由于其丰富的数据结构也可以被应用到其他场景。Redis的具有很多优势:
(1)读写性能高,10w次/s+的读速度,8w次/s+的写速度
(2)K-V,value支持的数据类型很多,包括字符串String、队列List、哈希Hash、集合Sets以及有序集合Sorted Sets五种不同的数据类型
(3)原子性,Redis的所有操作都是单线程原子性的
(4)特性丰富,支持订阅/发布模式,具有通知、设置key过期等特性
(5)在Redis 3.0版本引入了Redis集群,可用于分布式部署
Redis的功能有缓存,分布式锁以及消息队列。
Redis的一些特性
(1)value支持的数据类型有很多,如字符串、哈希以及集合等等
(2)Redis实例支持多数据库,一个Redis实例最多支持16个数据库,编号从0到15
(3)支持事务,multi指示事务的开始,exec指示事务的执行,discard指示事务的丢弃。所有的指令在exec之前都不执行,只是被缓存到服务器的一个队列里,只有在收到exec指令后才开始执行
Redis持久化
即将内存的数据持久化磁盘上,这样重启Redis进程之后,缓存的数据就不会丢失。当然也可以设置让Redis不做持久化,这样数据只会在内存中存在,当Redis进程重启时,数据就会丢失。关于Redis持久化有如下两种方式:
(1)RDB方式,即快照
RDB持久化方式会在一个特定的间隔保存那个时间点的数据快照。
(2)AOF方式,即追加式文件
AOF持久化方式则会记录每一个服务器收到的写操作。在服务启动时,这些记录的操作会逐条执行从而重建出原来的数据。写操作命令记录的格式跟Redis协议一致,以追加的方式进行保存。
Redis的速度为什么快
Redis采用的是基于内存的采用的是单进程单线程模型的KV数据库,由C语言编写。Redis之所以快的原因主要有:
(1)完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)。
(2)数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的。
(3)采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。需要注意的是,Redis新版本开始支持了多线程了。
(4)使用多路I/O复用的Reactor模型,非阻塞IO
需要注意的是,Redis是单线程的,只是在处理网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的。例如Redis进行持久化的时候会以子进程或者子线程的方式执行(具体是子线程还是子进程待读者深入研究)。至于Redis处理请求时使用单线程,官方解释说,Redis的瓶颈不在CPU,而在内存和网络带宽。
正是由于Redis处理请求是单线程的,所以不能充分利用CPU多核的特性。如果要想利用CPU多核特性,我们可以在一台机器上启动多个Redis实例就好了。
Redis客户端
Redis命令用于在redis服务上执行操作。要在redis服务上执行命令需要一个redis客户端。Redis安装之后自带redis-cli,就是Redis的客户端。
(1)连接本地redis服务
$ redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> PING
PONG
(2)连接远程redis服务
以下实例演示了如何连接到主机为127.0.0.1,端口为6379 ,密码为mypass的redis服务上。
$redis-cli -h 127.0.0.1 -p 6379 -a "mypass"
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> PING
PONG
备注:redis也有账号密码,这块待研究。
Redis整体的数据结构以及支持的数据类型
Redis数据结构
Redis内部整体的存储结构是一个大的hashmap(和Java中的HashMap结构很相似),内部是数组实现的hash,key冲突通过挂链表去实现,每个dictEntry为一个key/value对象,value为定义的redisObject。
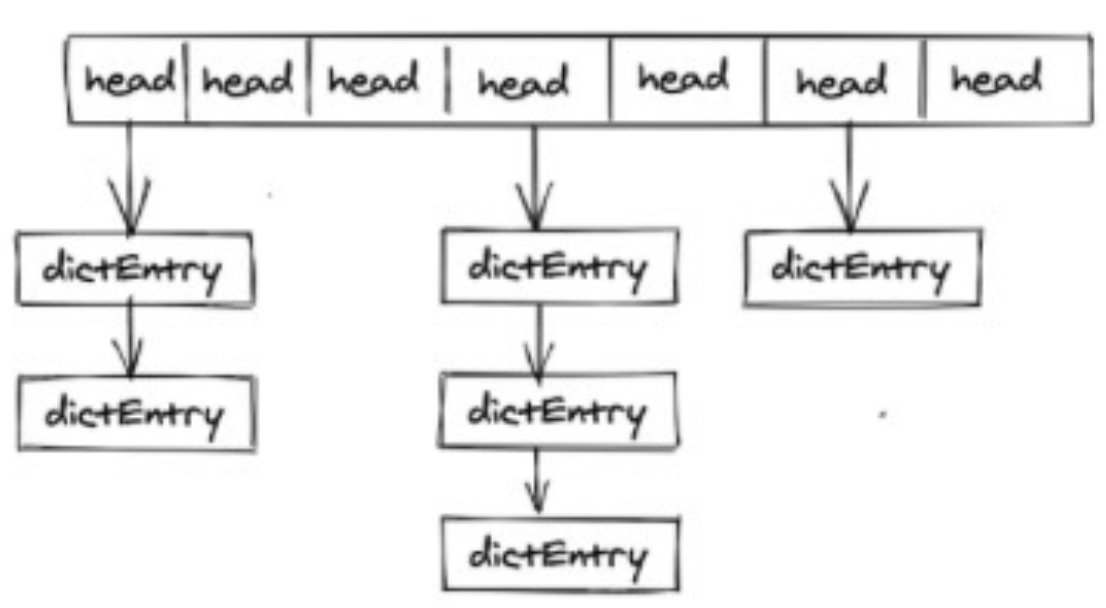
dictEntry是存储key->value的地方,再让我们看一下dictEntry结构体:
1 | /* |
因此通过dictEntry结构看到,redis中的value是一个redisObject,下面是redis中定义的redisObject结构:
1 | /* |
如上*ptr指向具体的数据结构的地址;type表示该对象的类型,即String/List/Hash/Set/Zset中的一个,但为了提高存储效率与程序执行效率,每种对象的底层数据结构实现都可能不止一种,encoding表示对象底层所使用的编码,也就是*ptr指向的数据类型,是Redis的内部数据类型,有如下八种:
REDIS_ENCODING_INT(long 类型的整数)
REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
REDIS_ENCODING_RAW (简单动态字符串)
REDIS_ENCODING_HT (字典)
REDIS_ENCODING_LINKEDLIST (双端链表)
REDIS_ENCODING_ZIPLIST (压缩列表)
REDIS_ENCODING_INTSET (整数集合)
REDIS_ENCODING_SKIPLIST (跳跃表和字典)
总结来说,String/List/Hash/Set/Zset是Redis对外提供的数据类型,而Redis实际存储时用的是内部类型,如下是对外类型和内部类型的对应关系:
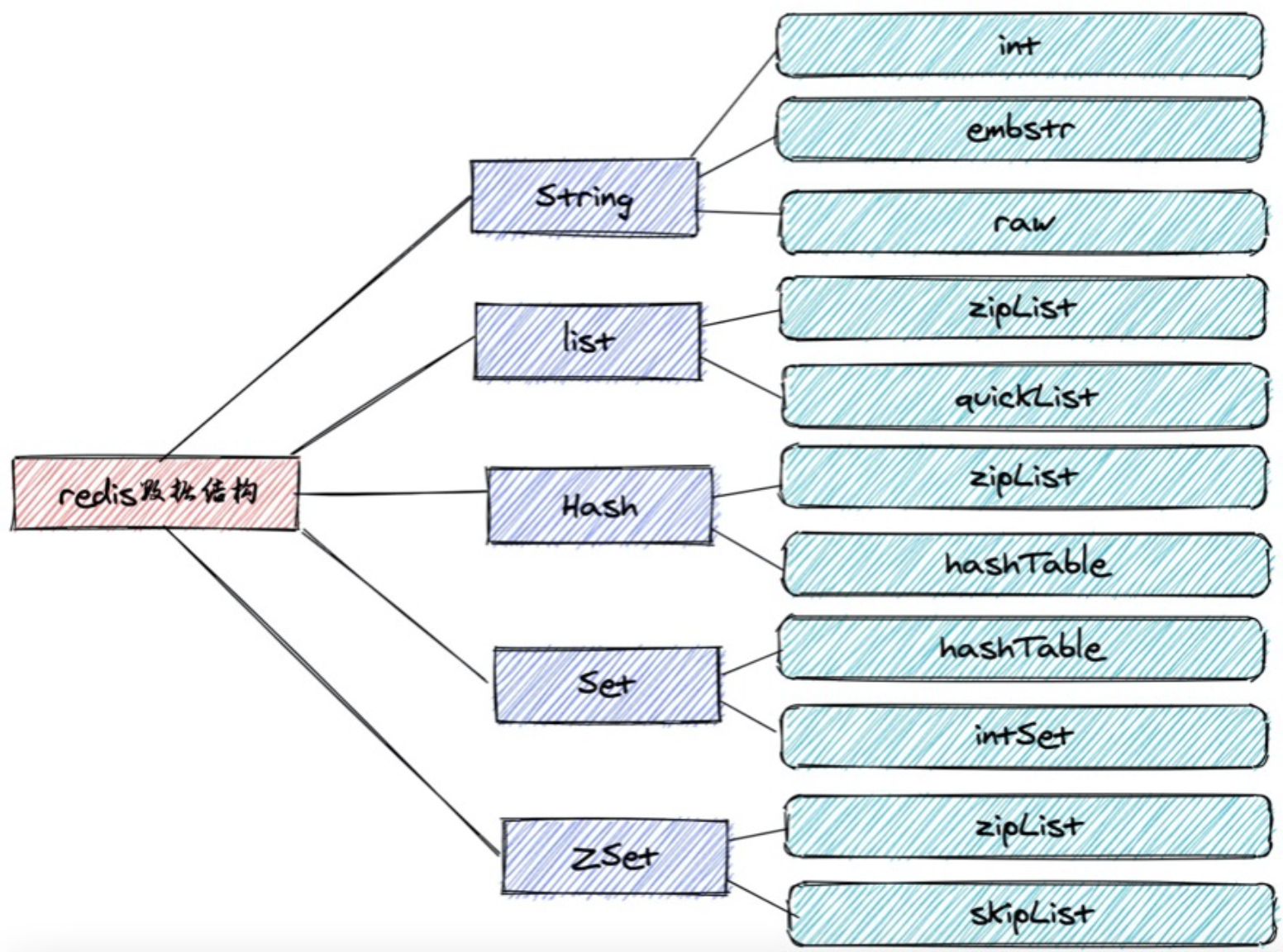
可以使用OBJECT ENCODING key命令来查看某个key存储的value的底层数据类型。
举例来说,String类型内部使用了int/embstr/raw类型,这也就是Redis能用String类型存储整型/浮点型数据的原因了。
Redis支持的五种数据类型
Redis支持的五种数据类型,string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
Redis命令
Redis命令简介
Redis命令格式如下:
COMMAND KEY_NAME [VALUE] [OPTION]
Redis的命令可以根据数据类型分为几类,常用的有:
SET
GET
DEL
EXISTS
EXPIRE
TTL
...
与keys相关操作命令
1 | DEL key #该命令用于在 key 存在时删除 key |
与string相关操作命令
1 | SET key value #设置指定 key 的值 |
与list相关操作命令
list即是链表。操作list的常用命令有rpush,lpop,lpush,rpop,lrange,llen等。命令举例如下:
1 | rpush myList value1 #向list的头部(右边)添加元素 |

与hash相关操作命令
hash类似于JDK1.8前的HashMap。操作hash的常用命令有hset,hmset,hexists,hget,hgetall,hkeys,hvals等。命令举例如下:
1 | hmset userInfoKey name "guide" description "dev" age “24” #初始化一个hash对象 |
与set相关操作命令
set类似于Java中的HashSet。Redis中的set类型是一种无序集合,集合中的元素没有先后顺序。操作set的常用命令有sadd,spop,smembers,sismember,scard,sinterstore,sunion等。
1 | sadd mySet value1 value2 #添加元素进去 |
与sorted set相关操作命令
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列,还可以通过score的范围来获取元素的列表。操作sorted set的常用命令有zadd,zcard,zscore,zrange,zrevrange,zrem等。
1 | zadd myZset 3.0 value1 #添加元素到sorted set中3.0为权重 |
Redis发布订阅
redis发布与订阅是一种消息通信的模式,发送者(pub)发送消息,订阅者(sub)接收消息。这使Redis可以用作消息队列。

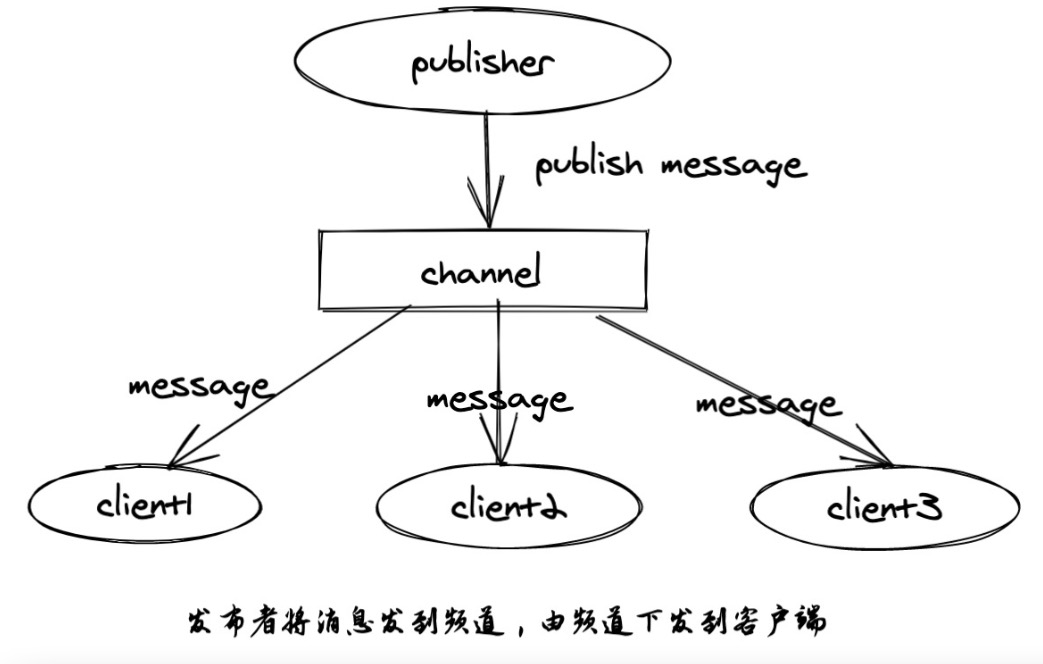
第一个redis客户端设置订阅某频道的消息:
redis 127.0.0.1:6379> SUBSCRIBE runoobChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "runoobChat"
3) (integer) 1
第二个redis客户端往某频道发布消息:
redis 127.0.0.1:6379> PUBLISH runoobChat "Redis PUBLISH test"
(integer) 1
redis 127.0.0.1:6379> PUBLISH runoobChat "Learn redis by runoob.com"
(integer) 1
# 订阅者的客户端会显示如下消息
1) "message"
2) "runoobChat"
3) "Redis PUBLISH test"
1) "message"
2) "runoobChat"
3) "Learn redis by runoob.com"
备注:订阅客户端订阅频道还支持模式匹配,如PUBLISH a.*,则该客户端会订阅a.b,a.c等等频道。
Redis内存淘汰机制
在Redis中,我们可以通过server.maxmemory去设置Redis最大使用内存大小,而当Redis内存数据集大小上升到一定程度的时候(Redis的内存已经快放不下了),Redis就会施行数据淘汰机制。Redis提供了一下6种数据淘汰机制:
Redis内存淘汰机制,保证Redis中的数据都是热点数据。Redis提供6种数据淘汰策略如下:
(1)volatile-lru(least recently used)
从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰。
(2)volatile-ttl
从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰。
(3)olatile-random
从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰。
(4)allkeys-lru(least recently used)
当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
(5)allkeys-random
从数据集(server.db[i].dict)中任意选择数据淘汰。
(6)no-eviction
禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。
当Redis要淘汰key并回收内存时,也有两种方式,一种是惰性删除(即不会立即删除,等下次来访问的时候再删除);一种是定期删除要淘汰的部分key。
Redis部署方式
(1)单机部署模式
(2)Master-Slave + Sentinel选举模式
(3)Redis Cluster模式
缓存几个可用性问题
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。解决方法如下:
(1)接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
(2)从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
(3)布隆过滤器。类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小。
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。解决方案如下:
(1)设置热点数据永远不过期。
(2)接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时候,进行熔断,失败快速返回机制。
(3)加互斥锁
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。解决方案如下:
(1)缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
(2)如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
(3)设置热点数据永远不过期
SpringBoot集成Redis
使用Spring Data Redis模块,构造RedisTemplate对象访问Redis实例,底层使用的是Jredis客户端,不过SpringBoot2.x开始,已经默认使用Lettuce客户端了。
其他闲杂
(1)Redisson是一个企业级的开源Redis Client,这个推荐使用。且这个Client还带有分布式锁支持,从而避免使用原生Client API实现分布式锁时考虑的一些复杂问题。
(2)从Redis 2.6版本起,Redis开始支持Lua脚本,通过内嵌支持Lua环境,执行脚本的常用命令为EVAL。整个Lua脚本中所有redis命令集合是一个原子性操作。Redis分布式的实现一般来说会用到Lua脚本。但是不保证事务(也就是部分命令失败,不会回滚),只能保证Lua脚本中命令集中间不会插入其他命令执行。至于事务,需要业务自己去保证。